Speed-up for finding an optimal partition line
This coding question derived from this question.
Consider an n by n grid of integers. The task is to draw a straight line across the grid so that the part that includes the top left corner sums to the largest number possible. Here is a picture of an optimal solution with score 45:
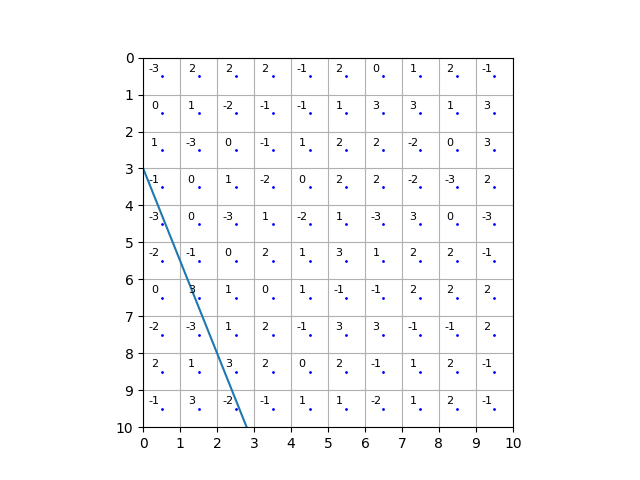
We include a square in the part that is to be summed if its middle is above or on the line. Above means in the part including the top left corner of the grid. (To make this definition clear, no line can start exactly in the top left corner of the grid.)
The task is to choose the line that maximizes the sum of the part that includes the top left square. The line must go straight from one side to another. The line can start or end anywhere on a side and not just at integer points.
The Python code given is:
import numpy as np
import fractions
def best_line(grid):
n, m = grid.shape
D = [(di, dj) for di in range(-(n - 1), n) for dj in range(-(n - 1), n)]
def slope(d):
di, dj = d
if dj == 0:
return float('inf') if di <= 0 else float('-inf'), -di
else:
return fractions.Fraction(di, dj), fractions.Fraction(-1, dj)
D.sort(key=slope)
D = np.array(D, dtype=np.int64)
s_max = grid.sum()
for grid in (grid, grid.T):
left_sum = 0
for j in range(grid.shape[1]):
left_sum += grid[:,j].sum()
for i in range(grid.shape[0]):
p = np.array([i, j], dtype=np.int64)
Q = p + D
Q = Q[np.all((0 <= Q) & (Q < np.array(grid.shape)), axis=1)]
s = left_sum
for q in Q:
if not np.any(q):
break
if q[1] <= j:
s -= grid[q[0],q[1]]
else:
s += grid[q[0],q[1]]
s_max = max(s_max, s)
return s_max
This code is already slow for n=30.
Is there any way to speed it up in practice?
Test cases
As the problem is quite complicated, I have given some example inputs and outputs.
The easiest test cases are when the input matrix is made of positive (or negative) integers only. In that case a line that makes the part to sum the whole matrix (or the empty matrix if all the integers are negative) wins.
Only slightly less simple is if there is a line that clearly separates the negative integers from the non negative integers in the matrix.
Here is a slightly more difficult example with an optimal line shown. The optimal value is 14.
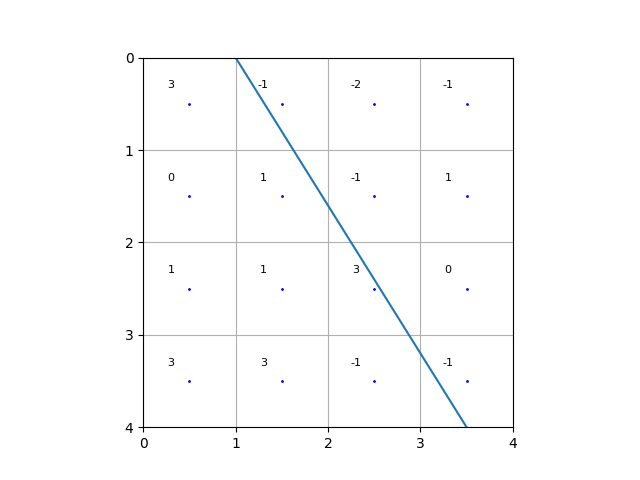
The grid in machine readable form is:
[[ 3 -1 -2 -1]
[ 0 1 -1 1]
[ 1 1 3 0]
[ 3 3 -1 -1]]
Here is an example with optimal value 0.
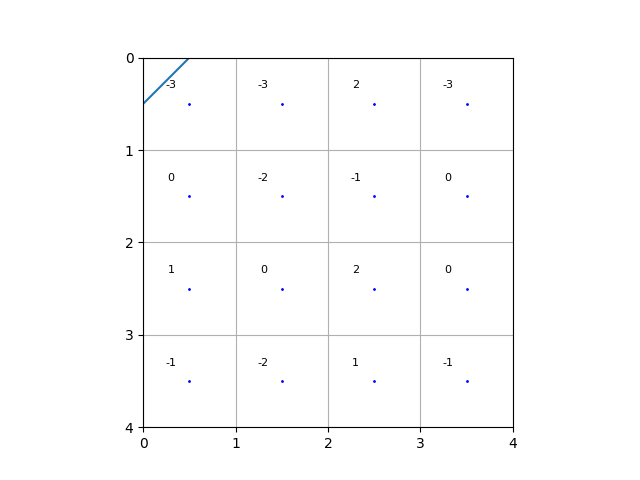
[[-3 -3 2 -3]
[ 0 -2 -1 0]
[ 1 0 2 0]
[-1 -2 1 -1]]
This matrix has optimal score 31:
[[ 3 0 1 3 -1 1 1 3 -2 -1]
[ 3 -1 -1 1 0 -1 2 1 -2 0]
[ 2 2 -2 0 1 -3 0 -2 2 1]
[ 0 -3 -3 -1 -1 3 -2 0 0 3]
[ 2 2 3 2 -1 0 3 0 -3 -1]
[ 1 -1 3 1 -3 3 -2 0 -3 0]
[ 2 -2 -2 -3 -2 1 -2 0 0 3]
[ 0 3 0 1 3 -1 2 -3 0 -2]
[ 0 -2 2 2 2 -2 0 2 1 3]
[-2 -2 0 -2 -2 2 0 2 3 3]]
In Python/numpy, an easy way to make more test matrices is:
import numpy as np
N = 30
square = np.random.randint(-3, 4, size=(N, N))
Timing
N = 30
np.random.seed(42)
big_square = randint(-3, 4, size=(N, N))
print(best_line(np.array(big_square)))
takes 1 minute 55 seconds and gives the output 57.
- Andrej Kesely's parallel code takes 1 min 5 seconds for n=250. This is a huge improvement.
Can it be made faster still?
TL;DR: This answer provides a much faster solution than the one of @AndrejKesely. Is also makes use of Numba, but the final code is more optimized despite being also more complex.
First simple implementation
The initial code is not efficient because it calls Numpy function in a loop. In such a case, Numpy functions are very expensive. Numba and Cython are the way to go to make the code significantly faster.
Still, operations on Nx2 arrays are not efficient, neither in Numpy nor in Numba. Moreover, generating temporary arrays (like Q) tends not to be optimal. The solution is typically to compute the array D on the fly without generating a temporary array Q.
Here is a naive relatively-fast implementation we can write based on this:
import numpy as np
import numba as nb
# Naive implementation based on the initial code: see below
def generate_D(n):
import fractions
def slope(d):
di, dj = d
if dj == 0:
return float('inf') if di <= 0 else float('-inf'), -di
return fractions.Fraction(di, dj), fractions.Fraction(-1, dj)
D = [(di, dj) for di in range(-(n - 1), n) for dj in range(-(n - 1), n)]
D.sort(key=slope)
return np.array(D, dtype=np.int64)
# Naive Numba implementation: see below
@nb.njit('(int64[:,::1], int64[:,::1], int64)')
def best_line_main_loop_seq(grid, D, s_max_so_far):
n, m = grid.shape
s_max = s_max_so_far
left_sum = 0
for j in range(m):
left_sum += grid[:,j].sum()
for i in range(n):
s = left_sum
for k in range(D.shape[0]):
qi = D[k, 0] + i
qj = D[k, 1] + j
if 0 <= qi and qi < n and 0 <= qj and qj < m:
if qi == 0 and qj == 0:
break
val = grid[qi,qj]
s += -val if qj <= j else val
s_max = max(s_max, s)
return s_max
# Main computing function
def best_line(grid):
n, m = grid.shape
D = generate_D(n)
s_max = grid.sum()
s_max = max(s_max, best_line_main_loop_par_unroll_transposed(grid.T.copy(), D, s_max))
s_max = max(s_max, best_line_main_loop_par_unroll_transposed(grid, D, s_max))
return s_max
# Benchmark
N = 30
np.random.seed(42)
big_square = np.random.randint(-3, 4, size=(N, N))
grid = np.array(big_square).astype(np.int64)
assert best_line(grid) == 57
%time best_line(grid)
The performance of this sequential code is not far from the one of the parallel implementation of @AndrejKesely (a bit slower on my machine, especially with a large N).
Faster generation of the array D
The above code is limited by the slow sort in generate_D(n) due to the rather inefficient fractions module, especially for small N values. The code can be made faster by comparing fractions in Numba directly. However, Numba unfortunately do not support keywords for the sort function so this feature needs to be reimplemented. This is a bit cumbersome to do manually, but the speed up worth the effort. Here is the resulting implementation:
@nb.njit('(UniTuple(int64,2), UniTuple(int64,2))')
def compare_fraction(a, b):
a_top, a_bot = a
b_top, b_bot = b
if a_bot < 0:
a_top = -a_top
a_bot = -a_bot
if b_bot < 0:
b_top = -b_top
b_bot = -b_bot
fixed_a = a_top * b_bot
fixed_b = b_top * a_bot
if fixed_a < fixed_b:
return -1
if fixed_a == fixed_b:
return 0
return 1
@nb.njit('(int64[::1], int64[::1])')
def compare_slope(a, b):
ai, aj = a
bi, bj = b
if aj == 0: # slope_a is special
if ai <= 0: # slope_a = (INF,-ai)
if bj == 0 and bi <= 0:
if -ai < -bi: return -1
elif -ai == -bi: return 0
else: return 1
else:
return 1
else: # slope_a = (-INF,-ai)
if bj == 0 and bi > 0: # slope_b = (-INF,-bi)
if -ai < -bi: return -1
elif -ai == -bi: return 0
else: return 1
else:
return -1
else:
if bj == 0: # slope_b is special
if bi <= 0: # slope_b = (INF,-bi)
return -1
else: # slope_b = (-INF,-bi)
return 1
slope_a = ((ai,aj), (-1,aj))
slope_b = ((bi,bj), (-1,bj))
res = compare_fraction(slope_a[0], slope_b[0])
if res == 0:
return compare_fraction(slope_a[1], slope_b[1])
return res
# Quite naive quick-sort, but simple one
@nb.njit('(int64[:,::1],)')
def sort_D(arr):
if len(arr) <= 1:
return
else:
pivot = arr[0].copy()
left = 1
right = len(arr) - 1
while True:
while left <= right and compare_slope(arr[left], pivot) <= 0:
left = left + 1
while compare_slope(arr[right], pivot) >= 0 and right >= left:
right = right - 1
if right < left:
break
else:
arr[left], arr[right] = arr[right].copy(), arr[left].copy()
arr[0], arr[right] = arr[right].copy(), arr[0].copy()
sort_D(arr[:right])
sort_D(arr[right+1:])
@nb.njit('(int64,)')
def generate_D(n):
D_list = [(di, dj) for di in range(-(n - 1), n) for dj in range(-(n - 1), n)]
D_arr = np.array(D_list, dtype=np.int64)
sort_D(D_arr)
return D_arr
The above generate_D function is more than 10 times faster on my machine.
Faster main loop
The naive main loop code provided above can be improved.
First of all, it can be parallelized though the code does not scale well (certainly due to the work imbalance caused by the break in the loop). This can be done efficiently with prange on the outer loop (using prange on the inner loop is not optimal because the amount of work is small and creating/joining threads is expensive).
Moreover, the loop can be unrolled so to reduce the number of conditional checks, especially on j. While the performance improvement can be significant (e.g. 2 times faster), this resulting code is also clearly less readable/maintainable (actually pretty ugly). This this a trade-off to pay since the operation is too complex for the Numba JIT to do it (and more generally most compilers).
Finally, the array access can be made more cache-friendly by virtually transposing the array so to improve the locality of memory accesses (i.e. accessing many items of a same row in the target grid rather than accessing different rows). This optimization is especially useful for large N values (e.g. >200).
Here is the resulting optimized main code:
@nb.njit('(int64[:,::1], int64[:,::1], int64)', parallel=True, cache=True)
def best_line_main_loop_par_unroll_transposed(grid, D, s_max_so_far):
m, n = grid.shape
s_max = s_max_so_far
all_left_sum = np.empty(m, dtype=np.int64)
left_sum = 0
for j in range(m):
left_sum += grid[j,:].sum()
all_left_sum[j] = left_sum
for j in nb.prange(m):
left_sum = all_left_sum[j]
for i in range(0, n//4*4, 4):
i1 = i
i2 = i + 1
i3 = i + 2
i4 = i + 3
s1 = left_sum
s2 = left_sum
s3 = left_sum
s4 = left_sum
continue_loop_i1 = True
continue_loop_i2 = True
continue_loop_i3 = True
continue_loop_i4 = True
for k in range(D.shape[0]):
qj = D[k, 1] + j
if 0 <= qj and qj < m:
qi1 = D[k, 0] + i1
qi2 = D[k, 0] + i2
qi3 = D[k, 0] + i3
qi4 = D[k, 0] + i4
mult = np.int64(-1 if qj <= j else 1)
if qj != 0:
if continue_loop_i1 and 0 <= qi1 and qi1 < n: s1 += mult * grid[qj,qi1]
if continue_loop_i2 and 0 <= qi2 and qi2 < n: s2 += mult * grid[qj,qi2]
if continue_loop_i3 and 0 <= qi3 and qi3 < n: s3 += mult * grid[qj,qi3]
if continue_loop_i4 and 0 <= qi4 and qi4 < n: s4 += mult * grid[qj,qi4]
s_max = max(s_max, max(max(s1, s2), max(s3, s4)))
else:
if continue_loop_i1 and 0 <= qi1 and qi1 < n:
if qi1 == 0 and qj == 0:
continue_loop_i1 = False
else:
s1 += mult * grid[qj,qi1]
s_max = max(s_max, s1)
if continue_loop_i2 and 0 <= qi2 and qi2 < n:
if qi2 == 0 and qj == 0:
continue_loop_i2 = False
else:
s2 += mult * grid[qj,qi2]
s_max = max(s_max, s2)
if continue_loop_i3 and 0 <= qi3 and qi3 < n:
if qi3 == 0 and qj == 0:
continue_loop_i3 = False
else:
s3 += mult * grid[qj,qi3]
s_max = max(s_max, s3)
if continue_loop_i4 and 0 <= qi4 and qi4 < n:
if qi4 == 0 and qj == 0:
continue_loop_i4 = False
else:
s4 += mult * grid[qj,qi4]
s_max = max(s_max, s4)
if not continue_loop_i1 and not continue_loop_i2 and not continue_loop_i3 and not continue_loop_i4:
break
for i in range(n//4*4, n):
s = left_sum
for k in range(D.shape[0]):
qi = D[k, 0] + i
qj = D[k, 1] + j
mult = np.int64(-1 if qj <= j else 1)
if 0 <= qi and qi < n and 0 <= qj and qj < m:
if qi == 0 and qj == 0:
break
s += mult * grid[qj,qi]
s_max = max(s_max, s)
return s_max
def best_line(grid):
n, m = grid.shape
D = generate_D(n)
s_max = grid.sum()
s_max = max(s_max, best_line_main_loop_par_unroll_transposed(grid.T.copy(), D, s_max))
s_max = max(s_max, best_line_main_loop_par_unroll_transposed(grid, D, s_max))
return s_max
Note that Numba takes a significant time to compile this function, hence the cache=True flag to avoid recompiling it over and over.
Performance results
Here are performance results on my machine (with a i5-9600KF CPU, CPython 3.8.1 on Windows, and Numba 0.58.1):
With N = 30:
- Initial code: 6461 ms
- AndrejKesely's code: 54 ms
- This code: 4 ms <-----
With N = 300:
- Initial code: TOO LONG
- AndrejKesely's code: 109 s
- This code: 12 s <-----
Thus, this implementation is more than 1600 times faster than the initial implementation, and also 9 times faster than the one of @AndrejKesely. This is the fastest one by a large margin.
Notes
The provided implementation can theoretically be optimized a bit further thanks to SIMD instructions. However, this is AFAIK not possible to easily do that with Numba. A native language need to be used to do that (e.g. C, C++, Rust). SIMD-friendly native languages (e.g. CUDA, ISPC) are certainly the way to go to do that quite easily. Indeed, doing that manually with native SIMD intrinsics or SIMD library is cumbersome and it will likely make the code completely unreadable. I expect this to be 2x-4x faster but certainly not much more. On CPU, this requires a hardware supporting fast SIMD masked-load instructions and blending/masking ones (e.g. quite-recent mainstream AMD/Intel x86-64 CPUs). On GPU, one need to care about maintaining SIMD lanes mainly active (not so simple since GPUs have very wide SIMD registers and warp divergence tends to increase due to the break and conditionals), not to mention memory accesses should be as contiguous as possible without bank conflits to get a fast implementation (this is probably far from being easy to do though here).