Multiple columns in Cassandra tables
I am wondering what happens when there are multiple Non-PK columns in a table. I've read this example: http://johnsanda.blogspot.co.uk/2012/10/why-i-am-ready-to-move-to-cql-for.html
Which shows that with single column:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value double,
PRIMARY KEY (schedule_id, time)
);
We get:
Now I wonder what happens when we have two columns:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value1 double,
value2 int,
PRIMARY KEY (schedule_id, time)
);
Are we going to end up with something like:
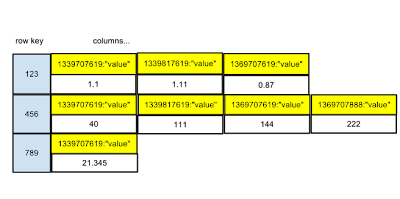
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
...
or rather:
row key columns...
123 1339707619:"value1":"value2" | 1339707679:"value1":"value2" | 1339707784:"value1""value2"
...
etc. I guess what I am asking is if this is going to be a sparse table given that I only insert "value1" or "value2" at a time.
In such situations if I want to store more columns (one per each type, eg. double, int, date, etc) would it be better perhaps to have separate tables rather than storing everything in a single table?
This post might help in explaining what is happening when composite keys are created: Cassandra Composite Columns - How are CompositeTypes chosen?
So essentially the table will look in the following way:
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
See also reference to secondary indexes: http://wiki.apache.org/cassandra/SecondaryIndexes
- When did C allow casting constants and variables to struct for assignment?
- Why in C can I initialize more values than the size of an array?
- What Values of Variables x and y Will Produce Incorrect Results When Testing for Overflow After Subtraction of x-y in the Following Program?
- How to write a general-type queue library in c?
- Which gcc and g++ version support which standard of c and c++?
- How to dereference a member in a struct whose definition is not visible?
- How to name a type in a meaningful way?
- In this case, how to achieve modularity and information hiding at the same time?
- What are Vectors and < > in C?
- Using c to create a file and write+read to it, what went wrong?
- Why does 1.0/100.0 == 0.1/10.0 give True?
- How to organize the receive msg and user current input in C network such that it's clean
- Using inclusive scan syntax in OpenMP in the C language
- Unable to understand context in book "OOP in C" by Axel Schreiner
- variable-length array in struct with TI compiler in C (socket programming)
- A faster way to test 32bpp DDBs for a valid Alpha channel
- How can I compile the zephyr example-application as a freestanding application?
- Why does my forked process sometimes overwrite data in a file?
- _Generic in C needs typecasting?
- Declaring/defining an unused variable changes the output from an unrelated variable
- How to use gdb to explore the stack/heap?
- How can I read an input string of unknown length?
- Confused by difference between expression inside if and expression outside if
- Fast Arc Cos algorithm?
- Discrepancy of `unsigned long` size between llvm and gcc in riscv32
- GCC (C) - error: 'x' redeclared as different kind of symbol
- Why does GCC’s static analyser falsely warn that a pointer to an allocated memory block itself stored in an allocated memory block may leak?
- c language gcc compiler *.i file #3 "" 2 what is this?
- How to make clang compile to llvm IR
- Hashtable implementation in C